Coupling pipeline
The Coupling pipeline is here to manage the connection and data exchange between Uptimai Solver and external software or databases. The screen is available only for methods where the coupling is required.
How to use the interface
Figure 1 shows the GUI layout before the pipeline is defined. The panel on the left serves as a container for a list of pipeline steps to be processed (currently empty). Down below, there is the Run Solver button. The button is inactive until the pipeline is ready up to the stage where all variables called during the process (especially output variables) are defined. Hovering with the mouse cursor over an inactive button shows a pop-up with a short description of missing definitions or faulty entries. To the right of the list of steps, there is a collapsible panel of Pipeline variables. The area on the right of the window is dedicated to controls and the definition of a pipeline step that is currently selected from the Coupling pipeline list.
Coupling pipeline
Steps of the pipeline can be added to the list via the + symbol at the top of the list next to the Add step label. The total number of coupling pipeline steps is not limited. Users can select from the following list of coupling step types, described in detail in a separate section of the manual:
Steps can be organized in the pipeline list. Each item is draggable with the mouse using the = symbol. The x removes the item (step) from the coupling pipeline. The correctly defined coupling pipeline makes the Run Solver button at the bottom of the screen active, allowing to access the Run Solver screen.
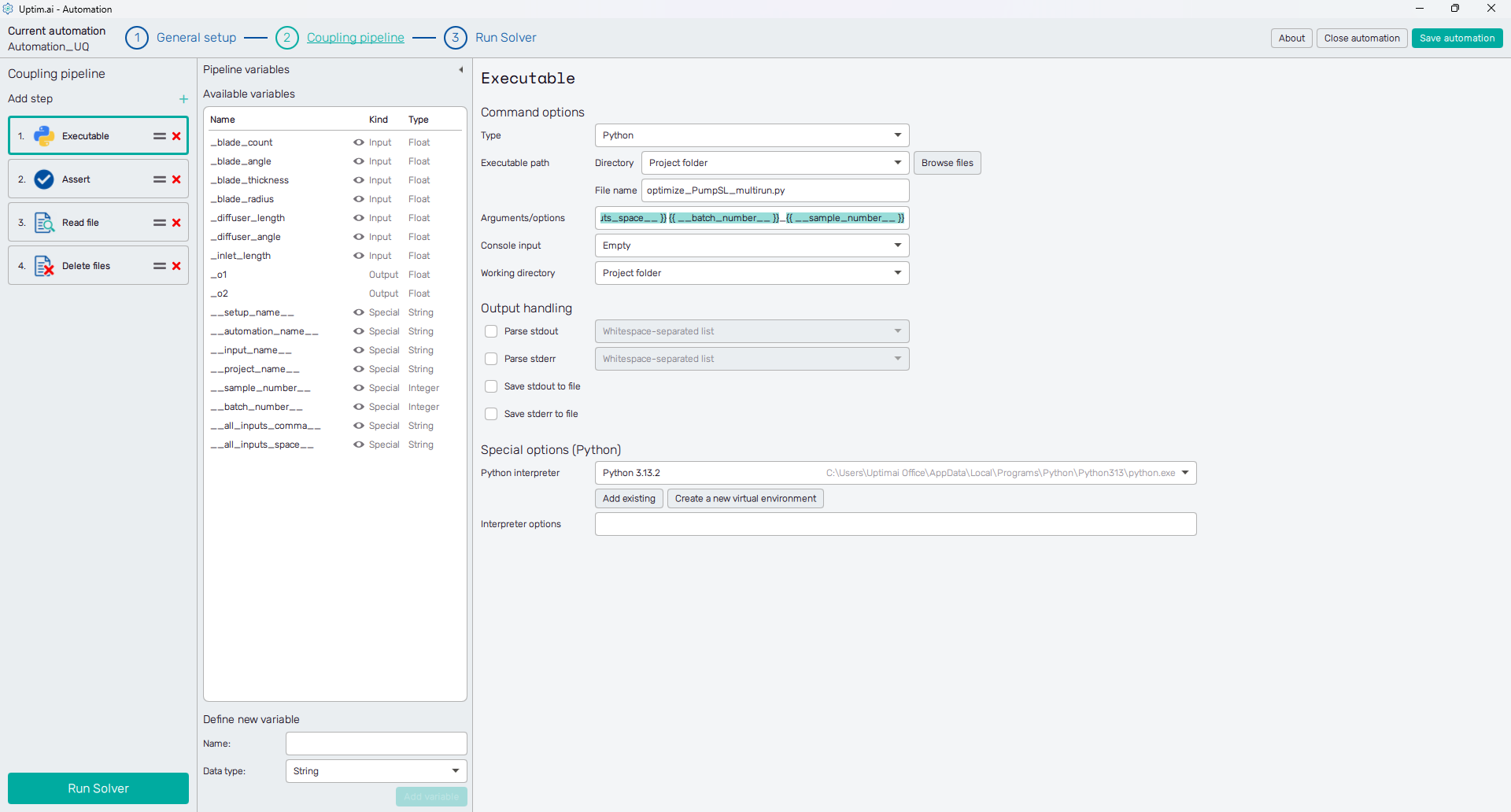
Pipeline variables
To the right of the Coupling pipeline, there is a collapsible panel of Pipeline variables. In the list of Available variables you can identify four main kinds:
- Input: Variables identified from the set of input files. Values of input variables are generated for each data sample by the Core Solver.
- Output: Values collected by the Automation program during the execution of the pipeline and passed back to the Core Solver. The number of output variables is defined in the General setup section of the automation session as the Number of outputs.
- Special: Values of these variables are generated automatically by the Automation program. These are related either to the project, set of inputs, or the pipeline execution process.
- User: User-defined variables. Usually used for internal checks or other auxiliary purposes.
Right-clicking the item from the list of variables shows the short menu offering to either Copy formatted name or to Copy raw name. These can be used later in the setup of coupling steps in almost every entry field accepting string. When the coupling pipeline is running, the formatted name of the variable is replaced with the variable’s value.
E.g. the definition of the name of a file holding a specific sample result could look like:
Result {{ __batch_number__ }} {{ __sample_number__ }}.txt
Then, the file name of the file holding the result of the 2nd sample from the 3rd batch would be automatically parsed as:
Result_3_2.txt